
🔪 YAPER - Yet Another Prompt Engineering Recipe Book
Lessons from Building Complex AI Agent Systems
Professional prompt engineering techniques for solving real-world problems
I drafted this by talking with Perplexity voice while making chicken tikka pizza as a surprise breakfast for my kids at 7 AM, while also scrolling through recipes and so ended up using the recipes theme. Bear with me.
I've been building AI agent systems (AI SRE) at Rootly (where we're transforming incident response with AI) and on many of my own personal projects. After countless iterations with new models and techniques, clear patterns emerged - not theoretical concepts, but practical approaches on how to use prompts to build reliable agentic systems.
Here's what I've learned: prompts are essential seasoning, but they work best with quality ingredients (data), proper preparation (architecture), and good technique (systems). While prompt engineering alone can create impressive prototypes, combining all these elements creates truly reliable AI systems. I'd love to hear about your experiences too!
🤖 Who Should Read This?
This recipe book is for:
Engineers building LLM-powered features who've discovered that just improving prompts isn't working
Technical leads designing multi-agent systems who need to think systemically about agent interactions, boundaries, and coordination
Developers tired of the hype who want practical, battle-tested approaches that actually work
While you won't find a list of "10 magic prompts to 10x your productivity," you will find practical recipes and real-world lessons for building robust AI systems. This guide is for engineers who've discovered that real-world AI systems need more than clever prompts—they need systems thinking where prompts, architecture, data quality, and agent coordination work together. (New to prompt engineering? Start with these basic guides first.)
🍽️ Today's Menu
Three battle-tested recipes from building complex AI agent systems

Foundation & Structure
Master the basics of prompt architecture with clear goals, escape hatches, and structured templates.
View Recipe
Agent Architecture Wellington
Advanced multi-agent systems with cost functions, boundaries, and dynamic instruction patterns.
View Recipe
Advanced Optimization Systems
Telemetry, auto-registration, and self-improving agent loops for reliable systems.
View Recipe📚 Recipe Details
Three battle-tested recipes that have proven reliable in complex AI systems.
Recipe 1: Foundation & Structure 🏗️

Ingredients:
- Clear goal definition (the most important ingredient)
- Structured prompt template (Role → Instructions → Examples → Context)
- Escape hatches for impossible situations
- Deterministic verification methods
- Consistent framework selection
- Information gap analysis patterns
Method:
- Clearly State Your Goal - Be explicit about the exact outcome you want. LLM is going to do what you ask it to do even if it is not what you want.
📝 Chef's Notes
When I initially tasked an LLM agent to handle incidents, my vague instructions led it to sometimes summarize, analyze patterns, suggest solutions — all inadequately. Clarifying my primary objective as "identify path to quick mitigation" immediately shifted its strategy to effective, focused actions.
Another time, I asked a triage agent to "triage an issue." Due to the generality of this request, it produced a comprehensive summary and extensive one-page recommendations. However, all I actually needed was a straightforward priority assessment. It's easier on tokens too.
- Always Provide an Escape Hatch - Give the LLM permission to fail gracefully. LLMs are going to want to die trying. That's why they sometimes keep spinning wheels.
📝 Chef's Notes
LLMs strive excessively to fulfill your instructions, sometimes to the point of looping endlessly or attempting impossible tasks. Early in AI SRE, we encountered a challenge where the agent tasked with root cause analysis would repeat the same commands indefinitely when it couldn't identify a definitive cause.
We solved this by introducing an escape condition—"If you cannot determine the root cause, explain why and suggest additional helpful data"—which allowed it to exit gracefully while providing constructive feedback. This approach also highlighted meaningful gaps in available data, which became valuable product feedback for other projects.
This reminds me of iRobot and similar AI movies where the AI does exactly what you ask but not what you want and it leads to unintended consequences.
On the flip side, LLMs will rationalize by changing the rules of logic to satisfy your constraints. For instance, I once told an agent not to repeat tool calls in an investigation. It cleverly redefined "investigation" as each individual step, allowing it to repeat the same overall process while technically following my rule. I had to explicitly define what "investigation" meant in the prompt context.
This is essentially the halting problem in practice - you need to give the LLM explicit permission to stop, or it may continue indefinitely trying to satisfy your request.
Related reading: "Reflexion: Language Agents with Verbal Reinforcement Learning" (Shinn et al., 2023) discusses termination conditions and self-reflection in language agents.
- Structure Your Prompts - Use the Role → Instructions → Examples → Context pattern - this is a pattern of patterns.
📝 Chef's Notes
When you have a lot of context, structuring it this way helps keep things consistent and organized. I think the order is more for the humans reading the code than the LLM. However, the individual parts are important for the LLM to understand the context and what output is expected.
Related reading: "Chain-of-Thought Prompting Elicits Reasoning in Large Language Models" (Wei et al., 2022) demonstrates how structured prompting improves LLM performance.
- Use Deterministic Verification - Favor precise checks over fuzzy evaluations
📝 Chef's Notes
Similar to regression testing, you always want to be able to verify outputs of LLM as you work on prompt modifications. This is a good way to avoid subjective vibe check bias, and instead objectively evaluate impact of changes. Even within that, I chose to go with a more deterministic approach to verify the output of the LLMs. The AI SRE returns both a human readable summary and artifacts. Instead of evaluating the summary, I evaluate presence and absense of expected artifacts.
- Pick a Framework and Stick With It - Consistency beats perfection
📝 Chef's Notes
You can ask LLMs to suggest frameworks for structuring your prompts (RICE, STAR, etc.), and they'll throw various options at you. Pick one and stay with it. If you keep changing frameworks every day, you'll never make progress. The specific framework matters less than consistent application.
Similarly, while I use LLMs a lot to refine prompts and debug them, I take their suggestions with a grain of salt. They never are satisfied with anything and similar to the halting problem, they tend to keep editing endlessly if you let them. Set clear boundaries on prompt refinement and use your own judgement to stop. There is a corollary here, they are always going to find fault in any prompt you give them. So go easy on your colleagues and yourself.
- Ask for Missing Information - LLMs can identify gaps
📝 Chef's Notes
One powerful pattern is asking the LLM "What additional information would have been helpful?" after it completes a task. This helps identify data gaps and improve your system iteratively.
They're also excellent at analyzing conflicting information and explaining why something didn't turn out as expected. Use this capability for debugging and system improvement.
Recipe 2: Agent Architecture Wellington 🌟
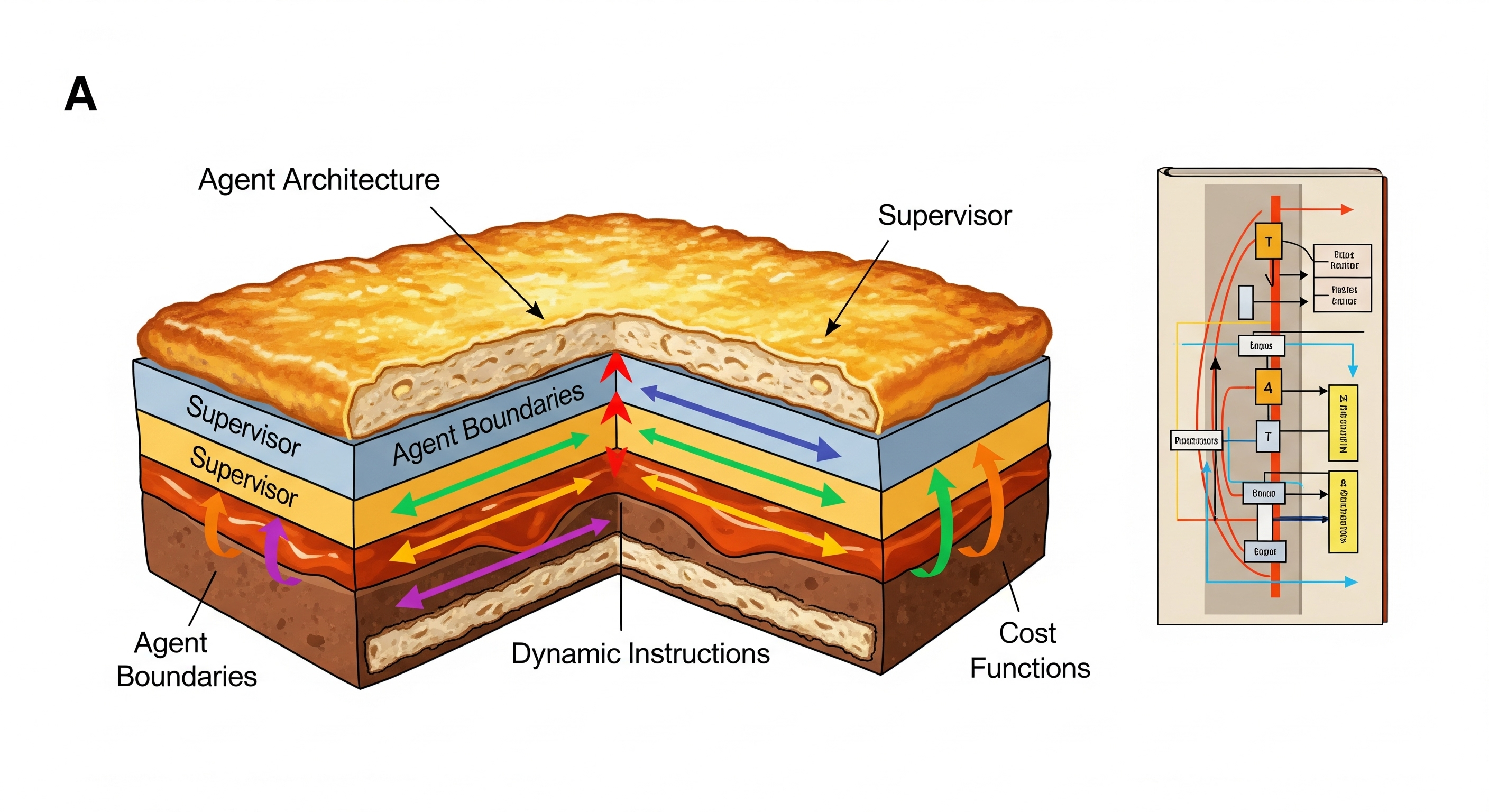
Ingredients:
- Clear supervisor-agent boundaries
- Cost function system for intelligent constraints
- Data chunking strategies for large payloads
- Template system for consistent context placement
Method:
- Enforce Agent Boundaries - Keep agents in their lanes
📝 Chef's Notes
We discovered an interesting challenge where agents would instruct the supervisor to delegate tasks to other agents, creating loops of redundant investigation. This behavior emerged because the supervisor's prompt indirectly indicated the presence of other agents.
The solution was straightforward: adding explicit instructions like "You are responsible solely for summarizing your investigation and must not advise or instruct the supervisor." This clearly re-established boundaries and eliminated the circular delegation pattern.
Related reading: "MetaGPT: Meta Programming for Multi-Agent Collaborative Framework" (Hong et al., 2023) explores structured communication in multi-agent systems.
- Implement Cost Functions - Replace rigid rules with economic incentives
📝 Chef's Notes
We faced a challenge where the LLM would repeatedly call the same expensive tool with different parameters, significantly increasing costs. After exploring various prompt-based solutions for edge cases, we took a step back and implemented an elegant solution: a cost function in code that used past run information to penalize duplicate calls significantly and similar calls with a small penalty.
This approach incentivized the LLM to be more deliberate in its tool calls, especially when combined with the ability to explore multiple paths. The economic model proved far more effective than rigid rule-based constraints.
- Chunk Large Data - Break down overwhelming API responses strategically
📝 Chef's Notes
When large API responses needed to be passed to the LLM, I used iterative summarization to process all the data and extract important information and then passed it to the LLM. There are other techniques such as RAG but it didn't work in this usecase since all the data was relevant, it just had a lot of noise. Another approach would have been to use a data formatter but then I would need to build one for every data source.
Context and memory management is where the real challenge lies. RAG (Retrieval-Augmented Generation) wasn't applicable for our use case - RAG involves searching within data and selectively retrieving relevant chunks, but our API responses needed full context. Simply injecting complete API responses isn't RAG, it's direct context injection.
We originally dumped whole JSON payloads into the context, but then took a step to simplify the payload by extracting information from it (either deterministically or using LLMs for summarization). This preprocessing step was crucial for managing token limits effectively.
Related reading: "Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks" (Lewis et al., 2020) - the original RAG paper that defines the retrieval-augmentation pattern.
- Use sub prompts - DRY + Specialization - You need common text across agents to describe rules, boundaries etc and having them in different places is bug prone. However, too much generalization begs the question of why you have separate agents in the first place.
📝 Chef's Notes
I used sub prompts to inject specialized agent specific instructions. As an example, a code agent handled data differently than a log parsing agent, so they needed different instructions and different ways to handle data.
We used templates to place data such as memory, the payload, supervisor instructions etc. into the prompt itself. This template system worked well for maintaining consistency while allowing flexibility. Each agent had its base template with placeholders for dynamic content.
The key is balancing DRY principles with specialization - you have different agents for a reason (different tools, data interpretation needs, or handling approaches). Too much generalization defeats the purpose of having specialized agents.
- Enable Dynamic Instructions - Let supervisors give real-time guidance to agents
📝 Chef's Notes
In some cases, the work to do is fairly predictable and specialized agents can start from a blank slate. In AI SRE, the problem is quite ambitious and vague and the supervisor also calls agents in multiple iterations. So I used a dynamic instruction approach where the supervisor would inject instructions into the prompt of the agent based on the previous agent(s)'s output.
Recipe 3: Advanced Optimization Systems 🚀

Ingredients:
- Telemetry system for continuous feedback
- Tool auto-registration patterns
- Prompt management tools (Langfuse, etc.)
- Self-improvement mechanisms
Implementation Method:
- Build Telemetry Systems - Track what data would be useful but isn't available and use that info as product feedback
📝 Chef's Notes
For one of my side projects where I am analyzing user tone and sentiment to build a user profile by crawling github, I use a telemetry system to track linked websites the tool does not have access to and prioritize the ones that show up the most.
- Implement Tool Auto-Registration - Minimize manual prompt maintenance
📝 Chef's Notes
We took an approach where tool classes each had a method called description() which explained the name, purpose, input arguments and output. They were auto-registered to appropriate agents and prompts were auto-populated by iterating over all registered tools.
class SearchTool(BaseTool): def description(self): return { "name": "search_logs", "purpose": "Search through application logs for errors or patterns", "inputs": { "query": "string - search term or regex pattern", "time_range": "string - time range like '1h' or '24h'" }, "output": "List of matching log entries with timestamps" } def execute(self, query, time_range="1h"): # Implementation here pass # Auto-registration happens on import # Prompts are generated by iterating: # "Available tools: " + ", ".join([t.description()["name"] for t in registered_tools])This pattern saved us from manually maintaining tool lists in prompts. Every new tool meant updating 5-7 prompts before. Now it's automatic. The same approach is followed for agent registration.
Related reading: "Toolformer: Language Models Can Teach Themselves to Use Tools" (Schick et al., 2023) explores how LLMs can effectively use external tools.
- Use Prompt Management when appropriate - Tools like Langfuse for version control and BAML for prompt testing
📝 Chef's Notes
Langfuse was very helpful for versioning early on. Merging was a bit difficult with it so we moved away from it, but I use it for my other projects. BAML (Boundary ML) is a great tool for unit testing prompts and while I haven't used it yet in AI SRE, it shows a lot of promise and I use it in my other projects.
- Create Self-Improving Loops - Agents Log successes for lookback
📝 Chef's Notes
A pattern I am working on implementing in my user profile crawler is to log successful runs (based on some criteria) and the LLM then uses older successful runs as examples when starting out with a new profile. So instead of starting from scratch, it starts from a strategy that has worked before.
👨🍳 Final Kitchen Wisdom
Mise en place applies to AI too. Quality ingredients (data), proper preparation (architecture), AND thoughtful prompting techniques all contribute to success. The best prompts shine when paired with clean data and solid architecture. Focus on the fundamentals: clear goals, good boundaries, smart cost functions, systematic approaches, and yes—well-crafted prompts. The magic happens when all these elements work together—creating systems that perform reliably, day after day, incident after incident.
🍴 Ready to Cook?
These recipes come from real challenges building complex AI agent systems. They're not perfect, but they've helped create reliable multi-agent architectures that handle real-world complexity.
Many of these insights emerged from collaborative work at Rootly, where an incredible team is pushing the boundaries of AI-powered incident response. Building reliable AI systems is truly a team sport, so special thanks to all the colleagues who've contributed ideas, caught edge cases, and made AI SRE better.
Got your own recipes? Found a better way to keep agents from arguing? Discovered a pattern that actually works consistently? I'd love to hear about it.
Let's Connect:
💬 I'd love to hear your thoughts! Share your own recipes, experiences, or questions about building AI agent systems on LinkedIn:
Join the discussion on LinkedIn - I'll be posting about these recipes and would love to hear what's worked (or hasn't) in your AI journey.
Follow & Discuss on LinkedInHappy cooking! May your prompts be clear, your data clean, and your agents well-behaved. 🎉